Golan Levin, Zach Lieberman, Jaap Blonk, Joan La Barbara, “Messa di Voce,” 2003
|
|||

Abbildung: Drei der Zwölf Software-Module von "Messa di Voce" von Levin, Lieberman und den Stimmakrobaten Blonk, & La Barbara |
|||
|
Die Schriftstellerin Diane Ackerman2 vergleicht Musik mit Sprache und bescheibt Musik als eine direkte emotionale Ausdrucksform, während Sprache eine rationale Ausdrucksform sei in der keine direktes Verhältnis zwischen den bezeichneten original Objekten, Ideen und Gefühlen besteht(Ackerman, 1990, 173). Betrachten wir die animierten Graphiken mit denen die Künstler intergieren werden wir uns bewusst dass sie eine gestische Qualität haben, ein isomorpes Verhältnis zwischen Lautstärke und Tonhöhe der Stimme, Position des Künstlers auf der Bühne und der Dynamik, Form und Farbigkeit der Grafiken. Sie führen einen Dialog zwischen der klingenden Stimme und den aus ihr resultierenden grafischen Formen. Beide unterstützen einander und erzeugen einen Kreislauf aus Aktion und Reaktion. Die gestische Qualität der Grafiken ist nicht "natürlich" sondern völlig das Ergebnis eines bewussten Gestaltungprozesses. Jeder Aspekt der Erscheinung und des Verhaltens der Grafiken ist bis ins Detail gestaltet und wird von den Software geleistet. |
|||
Transformation und Spatialität in “Messa di Voce”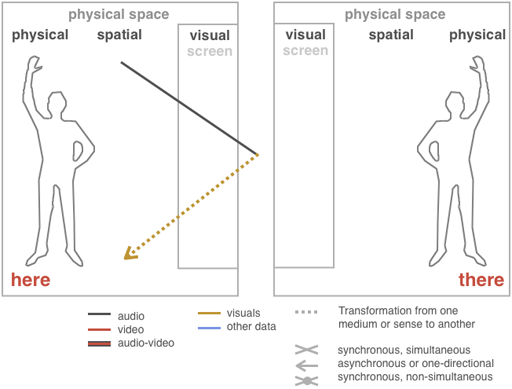
|
|||
|
Hier, Dort: Transformation und Spatialität: Der Klang der menschlichen Stimme wird zu animierten Grafiken transformiert mit denen in räumlichen Dimensionen interagiert werden kann. Die Projektionsfläche ist ausreichend gross um mit dem gesamten Körper räumlich zu interagieren. Es handelt sich nicht um eine telematische Applikation weshalb kein "Dort" (There) involviert ist. |
|||
Links:1. Videos der einzelnen Module können auf der Projektseite gefunden werden: http://www.tmema.org/messa/ Resourcen:2. Diane Ackerman (1991), "A Natural History Of The Senses," |
|||
| letzte Änderungen: 7.1.02008 0:53 About Kontakt Disclaimer Glossar Index |
|||