Golan Levin, Zach Lieberman, Jaap Blonk, Joan La Barbara, “Messa di Voce,” 2003Golan Levin and Zach Lieberman are media designers, programers and artists with a history of projects visualising data, real-time animation and sound. “Messa di voce” 1 is an interactive audio-visual voice performance in which two voice acrobats, Blonk and La Barbara, create unusual sounds with their voices, while interacting with twelve different modules of Levin’s and Lieberman’s software application. |
|||

Three of the twelve modules of Messa di Voce by Levin, Lieberman and voice artists Blonk, & La Barbara |
|||
|
Diane Ackerman compares music to speech and writes that music is a direct emotional language, while speech is a rational one, with no direct relationship to the original objects, ideas and feelings it describes (Ackerman, 1990, 173). If we look at the animated visuals with which the artists interact we see that they have a gestural quality, an isomorphic relationship between volume and pitch of the voice, position of the artist on the stage and dynamic, shape and colour of the visuals. They create a dialogue between their sounding voice and the resulting visuals, which both reinforce each other when they interact creating a loop of action and reaction. This gestural quality of the visuals is not natural but entirely the result of a conscious design process. Every aspect of the appearance and the behaviour of the visuals has been deeply designed and implemented into the software. |
|||
Transformation and spatiality in “Messa di Voce”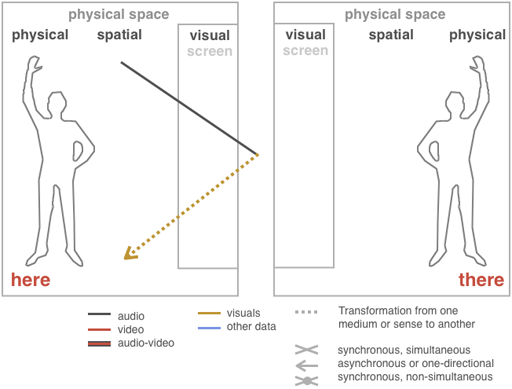
|
|||
|
Here, There: Transformation and Spatiality: The sound of the human voice is transformed into visuals that can be interacted with in spatial dimensions. The screen is so large it allows for spatial interaction. It is not a telematic application and thus involves no remote location or “there.” |
|||
Links:1. Videos of the different modules can be viewed on the project website at http://www.tmema.org/messa/ Resourcen:2. Diane Ackerman (1991), "A Natural History Of The Senses," |
|||
| last update: 1/7/02008 0:53 About Contact Disclaimer Glossary Index |
|||